

Хотя «L» в Large Language Models (LLMs) подразумевает огромный масштаб, реальность более нюансирована. Некоторые LLM содержат триллионы параметров, а другие эффективно работают с гораздо меньшим количеством.
Взгляните на несколько реальных примеров и практические последствия использования разных размеров моделей.
Размеры и классы размеров LLM
Как веб-разработчики, мы склонны думать о размере ресурса как о размере его загрузки. Документированный размер модели относится к числу ее параметров. Например, Gemma 2B означает Gemma с 2 миллиардами параметров.
LLM могут иметь сотни тысяч, миллионы, миллиарды или даже триллионы параметров.
Более крупные LLM имеют больше параметров, чем их меньшие аналоги, что позволяет им улавливать более сложные языковые отношения и обрабатывать тонкие подсказки. Их также часто обучают на более крупных наборах данных.
Вы могли заметить, что некоторые размеры моделей, такие как 2 миллиарда или 7 миллиардов, являются общими. Например, Gemma 2B, Gemma 7B или Mistral 7B . Классы размеров моделей являются приблизительными группировками. Например, Gemma 2B имеет приблизительно 2 миллиарда параметров, но не точно.
Классы размеров моделей предлагают практичный способ оценки производительности LLM. Думайте о них как о весовых категориях в боксе: модели в пределах одного класса размеров более сопоставимы. Две модели 2B должны иметь схожую производительность.
При этом меньшая модель может обеспечить ту же производительность, что и большая модель при выполнении определенных задач.

Хотя размеры моделей для самых современных LLM, таких как GPT-4 и Gemini Pro или Ultra, не всегда раскрываются, считается, что они составляют сотни миллиардов или триллионы параметров .

Не все модели указывают количество параметров в своем названии. Некоторые модели имеют суффикс с номером версии. Например, Gemini 1.5 Pro относится к версии 1.5 модели (следующей за версией 1).
Магистр права или нет?
Когда модель слишком мала, чтобы быть LLM? Определение LLM может быть несколько размытым в сообществе AI и ML.
Некоторые считают только самые большие модели с миллиардами параметров истинными LLM, в то время как меньшие модели, такие как DistilBERT , считаются простыми моделями NLP. Другие включают меньшие, но все еще мощные модели в определение LLM, опять же такие как DistilBERT.
Меньшие LLM для вариантов использования на устройстве
Более крупные LLM требуют много места для хранения и много вычислительной мощности для вывода. Они должны работать на выделенных мощных серверах со специальным оборудованием (например, TPU).
Нас как веб-разработчиков интересует, достаточно ли мала модель для загрузки и запуска на устройстве пользователя.
Но на этот вопрос сложно ответить! На сегодняшний день нет простого способа узнать, что «эта модель может работать на большинстве устройств среднего класса», по нескольким причинам:
- Возможности устройства сильно различаются в зависимости от памяти, характеристик графического процессора/процессора и т. д. Низкобюджетный телефон Android и ноутбук NVIDIA® RTX сильно отличаются. У вас могут быть некоторые данные о том, какие устройства есть у ваших пользователей. У нас пока нет определения базового устройства, используемого для доступа в Интернет.
- Модель или фреймворк, в котором она работает, могут быть оптимизированы для работы на определенном оборудовании.
- Не существует программного способа определить, может ли конкретный LLM быть загружен и запущен на определенном устройстве. Возможности загрузки устройства зависят от объема VRAM на GPU, среди прочих факторов.
Однако у нас есть некоторые эмпирические знания: сегодня некоторые модели с несколькими миллионами или несколькими миллиардами параметров могут работать в браузере на устройствах потребительского уровня.
Например:
- Gemma 2B с MediaPipe LLM Inference API (подходит даже для устройств, работающих только на CPU). Попробуйте .
- DistilBERT с Transformers.js .
Это зарождающаяся область. Можно ожидать, что ландшафт будет развиваться:
- Благодаря инновациям WebAssembly и WebGPU, поддержке WebGPU в большем количестве библиотек, новым библиотекам и оптимизациям можно ожидать, что пользовательские устройства смогут все эффективнее запускать LLM различных размеров.
- Ожидается, что более мелкие, но высокопроизводительные степени магистра права будут становиться все более распространенными благодаря появлению новых методов сокращения .
Соображения для магистров права (LLM) меньшего размера
При работе с небольшими LLM всегда следует учитывать производительность и размер загрузки.
Производительность
Возможности любой модели во многом зависят от вашего варианта использования! Меньший LLM, точно настроенный под ваш вариант использования, может работать лучше, чем более крупный общий LLM.
Однако в пределах одного модельного семейства меньшие LLM менее способны, чем их более крупные аналоги. Для того же варианта использования вам, как правило, нужно будет выполнить более быструю инженерную работу при использовании меньшего LLM.
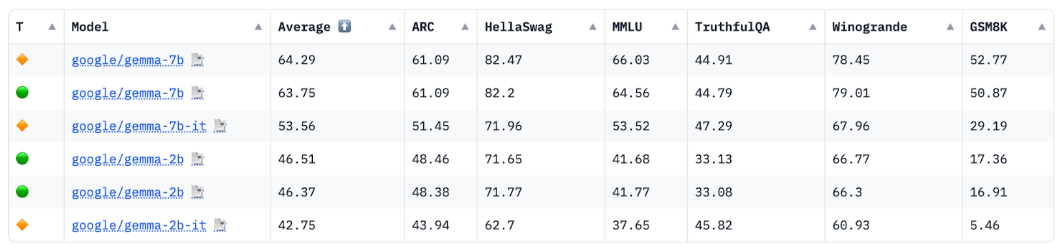
Источник: таблица лидеров HuggingFace Open LLM , апрель 2024 г.
Размер загрузки
Большее количество параметров означает больший размер загрузки, что также влияет на то, можно ли загрузить модель, даже если она небольшая, для использования на устройстве.
Хотя существуют методы расчета размера загрузки модели на основе количества параметров, это может оказаться сложным.
По состоянию на начало 2024 года размеры загрузки моделей редко документируются. Поэтому для случаев использования на устройстве и в браузере мы рекомендуем вам посмотреть на размер загрузки эмпирически, на панели «Сеть» в Chrome DevTools или с помощью других инструментов разработчика браузера.

Gemma используется с MediaPipe LLM Inference API . DistilBERT используется с Transformers.js .
Методы сжатия модели
Существует несколько методов, позволяющих значительно сократить требования модели к памяти:
- LoRA (адаптация низкого ранга) : метод тонкой настройки, при котором предварительно обученные веса замораживаются. Подробнее о LoRA .
- Обрезка : удаление менее важных весов из модели для уменьшения ее размера.
- Квантование : снижение точности весов от чисел с плавающей точкой (например, 32-битных) до представлений с меньшей разрядностью (например, 8-битных).
- Извлечение знаний : обучение меньшей модели для имитации поведения большей, предварительно обученной модели.
- Совместное использование параметров : использование одинаковых весовых коэффициентов для нескольких частей модели, что сокращает общее количество уникальных параметров.